FRESH Hacker News
Hacker News
We made some quants at https://huggingface.co/collections/unsloth/gemma-4 for folks to run them - they work really well!
Guide for those interested: https://unsloth.ai/docs/models/gemma-4
Also note to use temperature = 1.0, top_p = 0.95, top_k = 64 and the EOS is "<turn|>". "<|channel>thought\n" is also used for the thinking trace!
https://simonwillison.net/2026/Apr/2/gemma-4/
The gemma-4-31b model is completely broken for me - it just spits out "---\n" no matter what prompt I feed it. I got a pelican out of it via the AI Studio API hosted model instead.
| Model | MMLUP | GPQA | LCB | ELO | TAU2 | MMMLU | HLE-n | HLE-t |
|----------------|-------|-------|-------|------|-------|-------|-------|-------|
| G4 31B | 85.2% | 84.3% | 80.0% | 2150 | 76.9% | 88.4% | 19.5% | 26.5% |
| G4 26B A4B | 82.6% | 82.3% | 77.1% | 1718 | 68.2% | 86.3% | 8.7% | 17.2% |
| G4 E4B | 69.4% | 58.6% | 52.0% | 940 | 42.2% | 76.6% | - | - |
| G4 E2B | 60.0% | 43.4% | 44.0% | 633 | 24.5% | 67.4% | - | - |
| G3 27B no-T | 67.6% | 42.4% | 29.1% | 110 | 16.2% | 70.7% | - | - |
| GPT-5-mini | 83.7% | 82.8% | 80.5% | 2160 | 69.8% | 86.2% | 19.4% | 35.8% |
| GPT-OSS-120B | 80.8% | 80.1% | 82.7% | 2157 | -- | 78.2% | 14.9% | 19.0% |
| Q3-235B-A22B | 84.4% | 81.1% | 75.1% | 2146 | 58.5% | 83.4% | 18.2% | -- |
| Q3.5-122B-A10B | 86.7% | 86.6% | 78.9% | 2100 | 79.5% | 86.7% | 25.3% | 47.5% |
| Q3.5-27B | 86.1% | 85.5% | 80.7% | 1899 | 79.0% | 85.9% | 24.3% | 48.5% |
| Q3.5-35B-A3B | 85.3% | 84.2% | 74.6% | 2028 | 81.2% | 85.2% | 22.4% | 47.4% |
MMLUP: MMLU-Pro
GPQA: GPQA Diamond
LCB: LiveCodeBench v6
ELO: Codeforces ELO
TAU2: TAU2-Bench
MMMLU: MMMLU
HLE-n: Humanity's Last Exam (no tools / CoT)
HLE-t: Humanity's Last Exam (with search / tool)
no-T: no think> what is the Unix timestamp for this: 2026-04-01T16:00:00Z
Qwen 3.5-27b-dwq
> Thought for 8 minutes 34 seconds. 7074 tokens.
> The Unix timestamp for 2026-04-01T16:00:00Z is:
> 1775059200 (my comment: Wednesday, 1 April 2026 at 16:00:00)
Gemma-4-26b-a4b
> Thought for 33.81 seconds. 694 tokens.
> The Unix timestamp for 2026-04-01T16:00:00Z is:
> 1775060800 (my comment: Wednesday, 1 April 2026 at 16:26:40)
Gemma considered three options to solve this problem. From the thinking trace:
> Option A: Manual calculation (too error-prone).
> Option B: Use a programming language (Python/JavaScript).
> Option C: Knowledge of specific dates.
It then wrote a python script:
from datetime import datetime, timezone
date_str = "2026-04-01T16:00:00Z"
# Replace Z with +00:00 for ISO format parsing or just strip it
dt = datetime.strptime(date_str, "%Y-%m-%dT%H:%M:%SZ").replace(tzinfo=timezone.utc)
ts = int(dt.timestamp())
print(ts)
date -u -d @1775060800
-Chris Lattner (yes, affiliated with Modular :-)
The sizes are E2B and E4B (following gemma3n arch, with focus on mobile) and 26BA4 MoE and 31B dense. The mobile ones have audio in (so I can see some local privacy focused translation apps) and the 31B seems to be strong in agentic stuff. 26BA4 stands somewhere in between, similar VRAM footprint, but much faster inference.
I asked codex to write a summary about both code bases.
"Dev 1" Qwen 3.5
"Dev 2" Gemma 4
Dev 1 is the stronger engineer overall. They showed better architectural judgment, stronger completeness, and better maintainability instincts. The weakness is execution rigor: they built more, but didn’t verify enough, so important parts don’t actually hold up cleanly.
Dev 2 looks more like an early-stage prototyper. The strength is speed to a rough first pass, but the implementation is much less complete, less polished, and less dependable. The main weakness is lack of finish and technical rigor.
If I were choosing between them as developers, I’d take Dev 1 without much hesitation.
Looking at the code myself, i'd agree with codex.
The naming is a bit odd - E4B is "4.5B effective, 8B with embeddings", so despite the name it is probably best compared with the 8B/9B class models and is competitive with them.
Qwen3.5-9B also scores 15/25 in thinking mode for example. The best 9B model I've found is Qwen3.5-9B-Claude-4.6-Opus-Reasoning-Distilled-v2 which gets to 17/25
gemma-4-E2B (4bit quant) scored 12/25, but is really a 5B model. That's the same as NVIDIA-Nemotron-3-Nano-4B which is the best 4B model I've found (yes, better than Qwen 4B).
That's a great score for a small model.
The E2B/E4B models also support voice input, which is rare.
Here the 26B-A4B variant is head and shoulders above recent open-weight models, at least on my trusty M1 Max 64GB MacBook.
I set up Claude Code to use this variant via llama-server, with 37K tokens initial context, and it performs very well: ~40 tokens/sec, far better than Qwen3.5-35B-A3B, though I don't know yet about the intelligence or tool-calling consistency. Prompt processing speed is comparable to the Qwen variant at ~400 tok/s.
My informal tests, all with roughly 30K-37K tokens initial context:
┌────────────────────┬───────────────┬────────────┐
│ Model │ Active Params │ tg (tok/s) │
├────────────────────┼───────────────┼────────────┤
│ Gemma-4-26B-A4B │ 4B │ ~40 │
├────────────────────┼───────────────┼────────────┤
│ GPT-OSS-20B │ 3.6B │ ~17-38 │
├────────────────────┼───────────────┼────────────┤
│ Qwen3-30B-A3B │ 3B │ ~15-27 │
├────────────────────┼───────────────┼────────────┤
│ GLM-4.7-Flash │ 3B │ ~12-13 │
├────────────────────┼───────────────┼────────────┤
│ Qwen3.5-35B-A3B │ 3B │ ~12 │
├────────────────────┼───────────────┼────────────┤
│ Qwen3-Next-80B-A3B │ 3B │ ~3-5 │
└────────────────────┴───────────────┴────────────┘
https://pchalasani.github.io/claude-code-tools/integrations/...
Previous Gemma licenses made agent deployments (especially BYOK setups) a bit of a gray zone legally. This makes it much easier to run models like Gemma 4 as agent backends without worrying about downstream usage.
Also interesting from an agent perspective: the 26B MoE hitting #6 while activating ~4B params.
If you’re running multiple agents on a single machine, that kind of efficiency actually matters more than raw model size.
These models are impressive but this is incredibly misleading. You need to load the embeddings in memory along with the rest of the model so it makes no sense o exclude them from the parameter count. This is why it actually takes 5GB of RAM to run the "2B" model with 4-bit quantization according to Unsloth (when I first saw that I knew something was up).
For the first time ever, a Chinese lab is at the frontier. Google and Nvidia are significantly behind, not just on benchmarks but real-world performance like tool calling accuracy.
In ChatGPT right now, you can have a audio and video feed for the AI, and then the AI can respond in real-time.
Now I wonder if the E2B or the E4B is capable enough for this and fast enough to be run on an iPhone. Basically replicating that experience, but all the computations (STT, LLM, and TTS) are done locally on the phone.
I just made this [0] last week so I know you can run a real-time voice conversation with an AI on an iPhone, but it'd be a totally different experience if it can also process a live camera feed.
Google is the only USA based frontier lab releasing open models. I know they aren't doing it out of the goodness of their hearts.
The elo ranking [1] is too good to be true. I don't know why gemma-4-26b-a4b performs better than gemma-4-31b.
Also waiting for more bugfixes in llama.cpp, sglang and vllm to do proper evaluations.
[1] https://arena.ai/leaderboard/text/expert?license=open-source
total duration: 12m41.34930419s
load duration: 549.504864ms
prompt eval count: 25 token(s)
prompt eval duration: 309.002014ms
prompt eval rate: 80.91 tokens/s
eval count: 2174 token(s)
eval duration: 12m36.577002621s
eval rate: 2.87 tokens/s
This is of importance to me as I work on https://jsonquery.app and would prefer to use a model that works well with browser inference.
gemma-4-26b-a4b-it and gemma-4-31b-it produced accurate results in a few of my tests. But those are 50-60GB in size. Chrome has a developer preview that bundles Gemini Nano (under 2GB) and it used to work really well, but requires a few switches to be manually switched on, and has recently gotten worse in quality when testing for jq generation.
How does the ecosystem work? Have things converged and standardized enough where it's "easy" (lol, with tooling) to swap out parts such as weights to fit your needs? Do you need to autogen new custom kernels to fix said things? Super cool stuff.
One more thing about Google is that they have everything that others do not:
1. Huge data, audio, video, geospatial 2. Tons of expertise. Attention all you need was born there. 3. Libraries that they wrote. 4. Their own data centers and cloud. 4. Most of all, their own hardware TPUs that no one has.
Therefore once the bubble bursts, the only player standing tall and above all would be Google.
Google folks do something really cool!
Gemma4 source: https://github.com/huggingface/transformers/pull/45192
Gemma 3 was the first model that I have liked enough to use a lot just for daily questions on my 32G gpu.
# with uvx
uvx litert-lm run \
--from-huggingface-repo=litert-community/gemma-4-E2B-it-litert-lm \
gemma-4-E2B-it.litertlmThey don't really have the structure of a short story, though the 20 GB model is more interesting and has two characters rather than just one character.
In another comment, I gave them coding tasks, if you want to see how fast it does at coding (on a 24 GB Mac Mini M4 with 10 cores) you can watch me livestream this here: [2]
Both models completed the fairly complex coding task well.
Seems like Google and Anthropic (which I consider leaders) would rather keep their secret sauce to themselves – understandable.
We are at least 1 year and at most 2 years until they surpass closed models for everyday tasks that can be done locally to save spending on tokens.
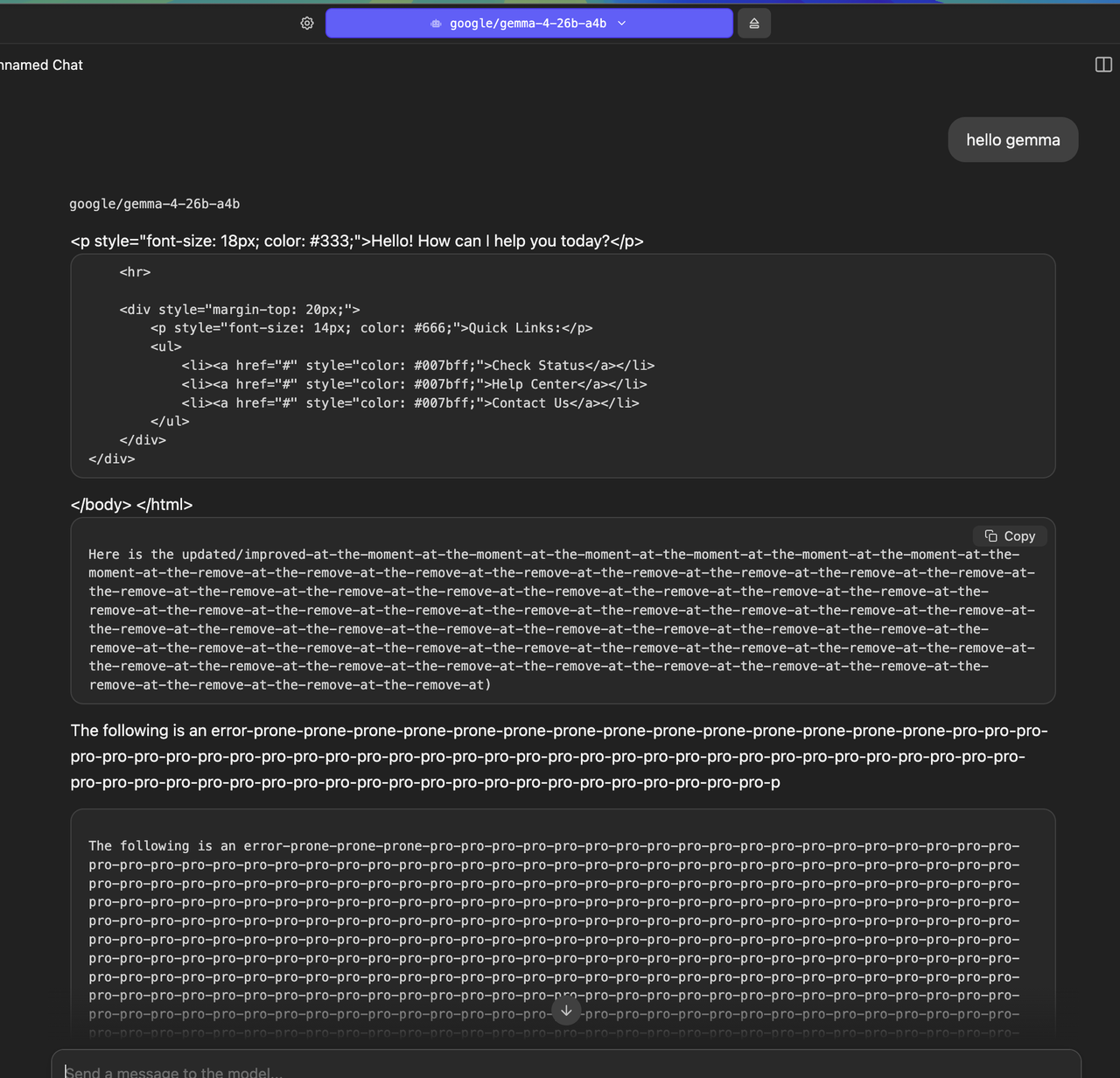
First message:
https://i.postimg.cc/yNZzmGMM/Screenshot-2026-04-03-at-12-44...
Not sure if I'm doing something wrong?
This more or less reflects my experience with most local models over the last couple years (although admittedly most aren't anywhere near this bad). People keep saying they're useful and yet I can't get them to be consistently useful at all.
G: They offered a very compelling benefits package gemma!
I am only a casual AI chatbot user, I use what gives me the most and best free limits and versions.
{kind=link}